
An editor from the popular news site The Verge tweeted that a new article on the first page of Google search results has been replaced by other sites that copied it. Danny Sullivan answers why this happens.
Copied content that ranks publishers frustrates them
Copied content outperforming the original is something publishers have expressed frustration with for many years.
Some complaints are due to a misunderstanding.
For example, when someone searches for a nonsensical phrase such as randomly picked words from an article, Google doesn’t know what to do with it. This is not a real search query and there is no answer to a nonsense phrase.
So what Google does is search defaults to text search, which means that Google returns search results based on words in the search query that match words on the web page.
The real test of whether copied content outperforms the original is when the copied content outperforms the original content for competitive keywords that users are already generating.
Should a page rank twice if it is in top score?
However, this emerging situation presents a different scenario. What has happened is that Google will not rank the title of an article at the top of the regular search results if that web page is already ranked in the top featured results, at the top of the web page.
Top stories is a featured result where Google displays news articles related to a search query.
So if someone searches for a headline, Google will usually display the article at the top of the search results in the Top Stories section.
But in this case, the original article doesn’t show up at the top of the normal search results because of what Google calls deduplication, an algorithm that prevents the same page from ranking twice.
So the question is, should Google rank the same page twice, once in top stories and again at the top of regular search results?
The entire front page consists of plagiarized content
Someone from The Verge tweeted that aside from Google’s featured news section at the top of the search results, a search for a headline from a new article resulted in Google showing a full top ten headlines consisting of nothing but plagiarized content.
The person tweeted:
Hey Google, I just looked up a title that was posted on my website and the full first page after the newsbox had websites stealing our content. The Verge didn’t show up until page 2.
This problem is getting worse.”
Hey Google, I just looked up an address that was posted on my website and the entire first page after the newsbox had websites stealing our content. The Verge didn’t appear until page 2.
This problem is getting worse. pic.twitter.com/Ox2AMYOt2Q
– Dieter Bohn (@backlon) January 18, 2022
Google’s Danny Sullivan acknowledged that writers who search using a headline expect to see their articles ranked at the top of the search results, not on the second page.
But he also noted that searching by headline is not necessarily how regular searchers will search.
Danny’s response is debatable. A reasonable argument can be made that many people look for the title of an article when they want to find it to share with a friend or on social media. So there is a real reason why people other than the author of the article would search for an article title.
tweeted Google’s Danny Sullivan:
We’ll take a look. I know searching by title is common for writers and yes, I’d expect this to show up first for that. But it doesn’t reflect how most people might search for that content (and how they might search, I actually find it). But again, We will look to improve.”
Danny then went on to explain why the original article was arranged on page two of its headline:
Here’s a follow up of what’s going on and what to look for. You mentioned this, but it’s not clear from the screenshot that your article is the first thing on the page (as shown). Since it’s showing in Top Stories, it’s been removed from the rest of the page… pic.twitter.com/YWCtcPAThZ
– Danny Sullivan (@dannysullivan) January 18, 2022
Data deduplication can often come in handy. Doing this research the way a user might by using solution search terms instead of unusual terms in the title you are at the top in top stories plus removing multiples means there is more variety than other posts…. pic.twitter.com/638IAZLWIV
– Danny Sullivan (@dannysullivan) January 18, 2022
In searches like this, our systems will also generally endeavor to bring up the most useful and reliable information they can. This is why you don’t see many duplicates of your article appearing. Duplicates certainly exist, but it is not useful to show them….
– Danny Sullivan (@dannysullivan) January 18, 2022
Search queries that lead to alternative search results
Danny Sullivan’s following tweet explains how a search query with a lot of terms, such as a keyword, causes the Google algorithm to leak and start returning search results that look a lot like old keyword searches, where the search results don’t depend on the search intent or Links but only based on the keywords themselves.
This is what Danny tweeted:
This leads to targeted searches. As I said before, this is very common among authors. I was doing it all the time myself. But address searches usually contain a lot of terms, so our systems turn to return pages with those terms…
– Danny Sullivan (@dannysullivan) January 18, 2022
As I mentioned above, there is search intent behind headline search. Google may not have recognized “title-oriented searches” as a search target that the algorithm should be aware of.
Danny continued with his answer:
This means that authors are more likely to find duplicates, even though with typical searches made by readers, they are less likely to turn up. But our deduplication feature may still work even for those, as it was in this case….
– Danny Sullivan (@dannysullivan) January 18, 2022
Like I said, data deduplication can come in handy. But we also understand the concern this might raise. We’ve been doing this with Top Stories since last May, but we’ll revisit this to see if we should continue or maybe make other changes.
– Danny Sullivan (@dannysullivan) January 18, 2022
Also, I’m still checking this out, but I think this deduplication is particularly unique in that it only happens with top stories if there is only one story shown or maybe only for the first story shown.
– Danny Sullivan (@dannysullivan) January 18, 2022
Just to finish with the additional clarification I promised, we de-duplicate a link from the web results if the link appears as the first link in Top Stories and if the Top Stories box appears before the web results. If it comes after that, we don’t. And again, this is something we’re reviewing.
– Danny Sullivan (@dannysullivan) January 19, 2022
News articles and deduplication
Duplicate elimination is when Google tries to prevent a single article from being ranked twice in the search results. Danny Sullivan has stated that the reason an article does not appear in the normal search results is if it is already ranking in Top Stories and if Top Stories is ranking at the top of the page.
So the question is, is this a situation where the web page has to rank twice, because the user might want to see the original article at the top of the search results, even if it’s already in the top stories section?
Once the Top Stories section is gone, the news article should rank higher in the search results.
Content ranks first after Top Stories ends
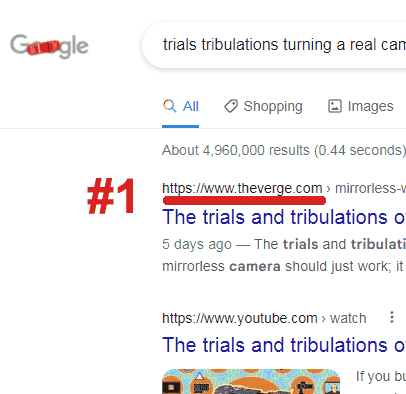
And this, as can be seen in the screenshot above, is what is happening now.
This is an interesting question as Google has to decide what is fair to the publisher and what is beneficial to the searcher.





