
Do you want to get a better ranking of your product listings on search engines?
Do you feel your success is as limited as your crawl budget?
Effectively ranking thousands of products, hundreds of categories, and millions of links requires a level of organization that can sometimes feel out of reach.
This is especially true when the performance of your ecommerce site depends on a limited crawling budget or offline teams.
For large e-commerce websites, this is an enormous challenge.
In this post, you will find proven solutions to some of the most pressing technical SEO problems plaguing sites like yours. You’ll learn how to address issues with crawl budget, site structure, internal linking, and more that are holding back your site’s performance.
Let’s go to her.
1. Crawl budget is often too limited to provide actionable insights
Growing your ecommerce business is great, but it can lead to massive page volume and a disorganized and outdated website structure.
The incredible growth of your company is likely to result in:
- The budget crawl SEO needs are extensive.
- prolonged crawls.
- High crawl budget waste from outdated content that can’t be easily missed, such as orphan pages and zombie pages, that you no longer need to crawl or index.
- Reports full of basic technical errors repeated in millions of pages are hard to follow.
- Incomplete and fragmented crawl data, or partial crawls.
Try to solve search engine optimization problems using Partial crawls are not a great idea; You won’t be able to locate all the errors, causing you to make SEO decisions that could do more harm than good.
Whether your crawling budget constraints are from website size or desktop based crawling tools, you need a solution that allows you to fully review and understand your website – without limits.
Solution: Use raw logs instead of crawl reports
To get around the issue of slow and limited crawl budgets, we recommend using raw logs instead of crawl reports.
Raw records give you the ability to:
- Monitor crawling, indexing, and detailed content analysis at a more affordable price.
- Understand which pages affect your crawl budget and optimize accordingly.
- Get rid of critical errors right after updating the product.
- They allow you to fix problems before Google bots discover them.
- You can quickly identify pages with 2XX, 3XX, 4XX, and 5XX status codes.
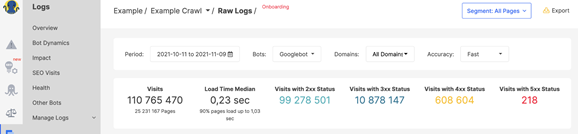
Using the raw history tool also gives you the exact picture of the site’s SEO efficiency.
You’ll be able to pull up reports that show how many pages are in your site structure, which pages are getting search bot traffic, and which pages are getting impressions in the SERPs.
This gives you a clearer picture of where build and crawl issues are occurring, at what depth.
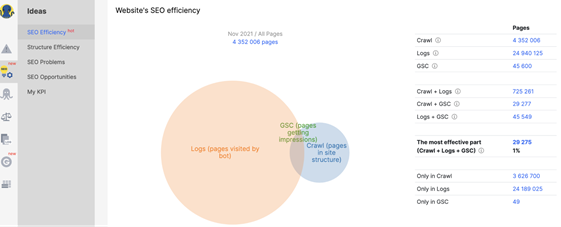 Screenshot from JetOctopus, November 2021
Screenshot from JetOctopus, November 2021For example, we can see that there are more than 4 million pages in the above site structure.
Only 725,161 were visited by search bots.
And only 29,277 of those pages are ranking and getting impressions.
24,189,025 pages visited by search bots that are not even part of the structure of the site.
What a missed opportunity!
How to spot and fix SEO crawling issues faster with raw logs
Implement an unlimited SEO analysis tool that can crawl entire websites of any size and structure.
Super fast, JetOctopus can crawl up to 250 pages per second or 50,000 pages in 5 minutes, in order to help you understand how your crawl budget will be affected.
Simply:
- Create an account on JetOctopus.
- Access the Impact section.
- Evaluate crawling and missing pages.
In seconds, you can measure the percentage of SEO-effective pages and see how to improve.
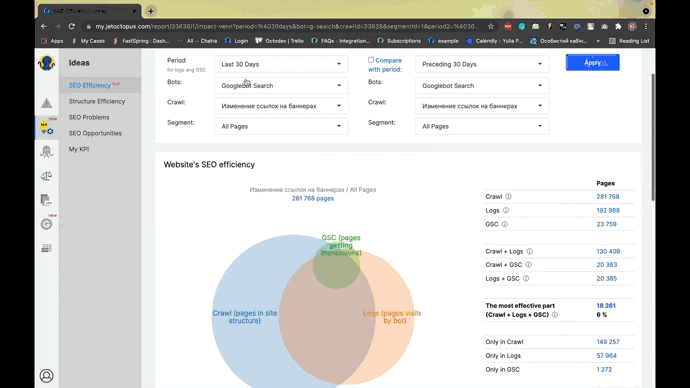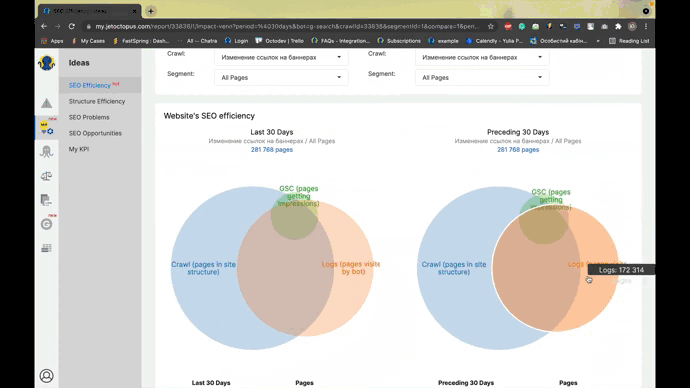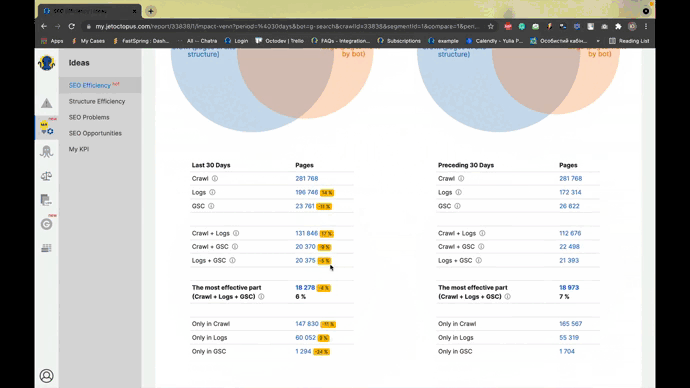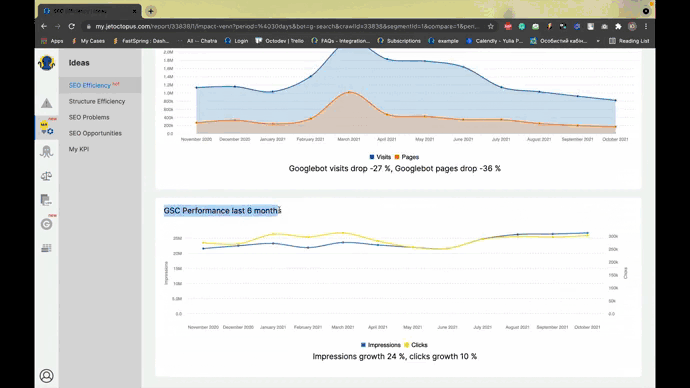 Screenshot from JetOctopus, November 2021
Screenshot from JetOctopus, November 2021Our history analyzer tracks crawl budget, zombie pages, orphan pages, accessibility errors, crawl deficiency areas, bot behavior by distance from index by content volume, inbound links, most active pages, and more.
With effective visualization, you can boost indexability while optimizing your crawl budget.
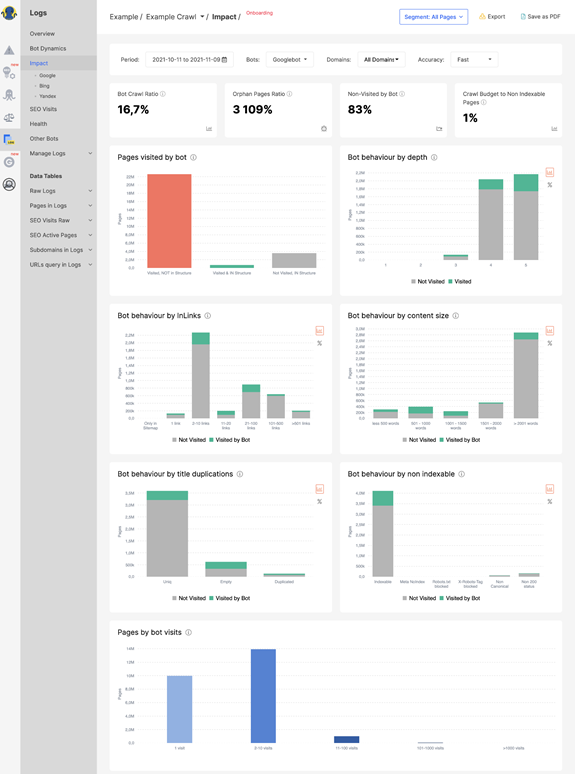 Screenshot from JetOctopus, November 2021
Screenshot from JetOctopus, November 2021How do?
Optimizing your crawl budget is central to any SEO efforts and even more so for large sites. Here are some points to help you get started.
Determine if your crawl budget is being wasted.
Log file analysis can help you identify the causes of wasted crawl budget.
Visit the Log File Analysis section to determine this.
Get rid of error pages.
Review the crawling of the site by analyzing the log file to find pages that may have 301, 400, or 500 errors.
Improve crawling efficiency.
Use SEO crawling and log file data to identify discrepancies between crawled and indexed pages. Consider the following to improve crawl efficiency.
- Ensure that the GSC parameter setting is updated.
- Check if any important pages are included as non-indexable pages. The data in the log files will help you locate them.
- Add disallow paths in your robots.txt file to save your crawl budget for priority pages.
- Add relevant noindex and canonical tags to indicate their level of importance to search bots. However, noindex tags do not work well in the case of multimedia resources, such as video files and PDFs. In such cases, use the robots.txt file.
- Find disallowed pages crawled by search bots.
2. Managing a huge internal linking structure can be complex
Internal linking is one of the best ways you can tell Google what is on your website.
When you create links to your products from pages on your site, you give Google a clear crawl path in order to rank your pages.
Google’s crawlers use a website’s internal link structure and anchor text to derive contextual meaning and discover other pages on the site.
 Screenshot from SearchEngineJournal.com, November 2021
Screenshot from SearchEngineJournal.com, November 2021However, creating a file internal linking structure Difficult on large scale websites.
Keeping up with internally linked products that are constantly coming in and out isn’t always sustainable on a large e-commerce site.
You need a way to find out where the dead occur during a Google crawl.
Why is the internal linking structure important?
Google relies on internal linking to help it understand how visitors can quickly and easily navigate a website.
If your homepage ranks well for a particular keyword, internal links help distribute your PageRank to other, more focused pages throughout the site. This helps those linked pages rank higher.
The solution: Find crawl dead ends with interconnected structure efficiency tools
Our efficient threading architecture solves this problem by giving you a clear view of your site’s internal linking health.
- On the dashboard, go to Ideas -> Structure Efficiency.
- This screenshot shows the list of directories on a website, pages in that directory, percentage of indexable pages, average number of internal links to a page within that directory, robot behavior here, SERP impressions and clicks. Clearly reflects SEO efficiency through directories to analyze and multiply positive experiences.
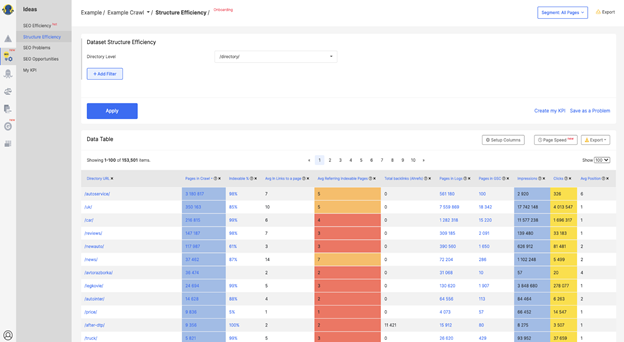 Screenshot from JetOctopus, November 2021
Screenshot from JetOctopus, November 2021Check out how our customers are DOM.RIA double your Googlebot visits through his experience.
3. SEO issues on JavaScript websites are difficult to troubleshoot
JavaScript is the cornerstone of responsive website design, enabling developers to improve interactivity and complexity in their applications. This is why it is used in large marketplaces like Amazon and eBay.
However, JavaScript websites have two problems:
- Creepability: JS content limits the crawler’s ability to navigate the website page by page, which affects its indexability.
- get: Although the crawler will read the JS page, it can’t know what the content is about. Thus, they will not be able to rank pages for relevant keywords.
As a result, the administrators of e-commerce sites cannot decide which pages are shown and which are not.
Solution: Use an advanced crawler that can render JavaScript as Googlebot
Traditionally, SEO crawlers have not been able to crawl JavaScript websites. But JetOctopus is one of the most advanced crawlers, with JavaScript rendering functionality.
In JS Performance, you’ll find insights into JavaScript execution – specifically First Paint, First Contentful Paint, and page load – and the time required to complete all JavaScript requests.
It also displays JS errors.
Here’s how to get this feature working for you:
- Go to JS Performance in the Crawler tab.
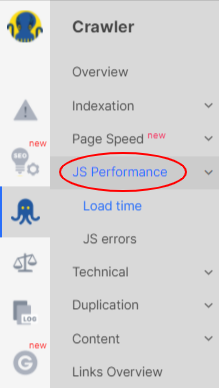 Screenshot from JetOctopus, November 2021
Screenshot from JetOctopus, November 2021- Display your website as a Googlebot with JavaScript. This GIF demonstrates the process.
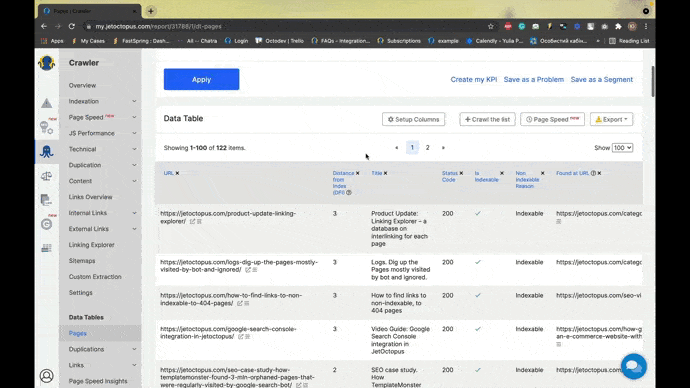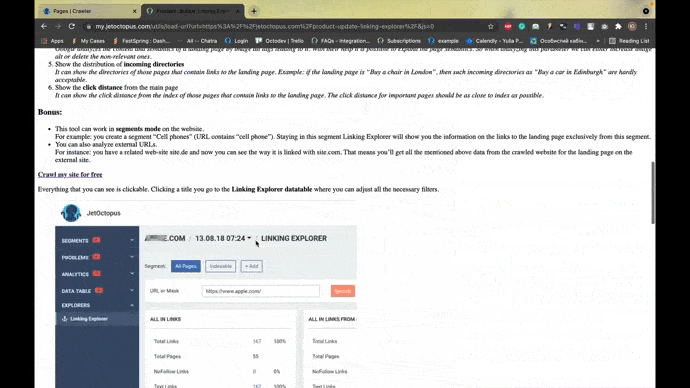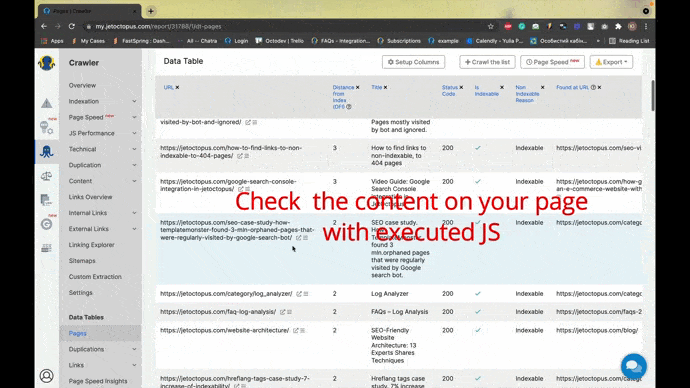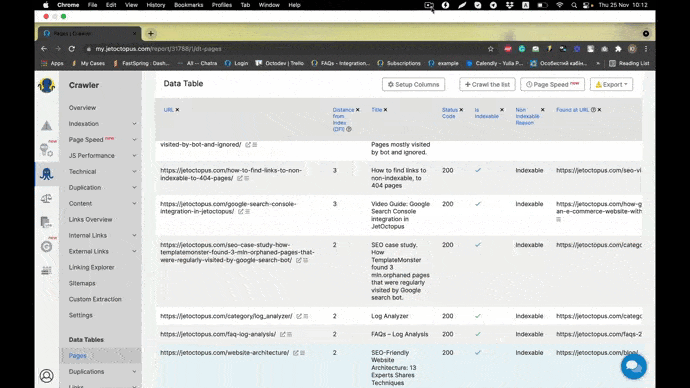 Screenshot from JetOctopus, November 2021
Screenshot from JetOctopus, November 20214. Few tools provide in-depth insights into large websites
Basic web fundamentals and page speed are important technical SEO metrics to monitor. However, a few tools track this page by page.





