
Latent semantic indexing (LSI) is a method of indexing and retrieving information used to identify patterns in the relationships between terms and concepts.
With LSI, a mathematical technique is used to search linguistically Related terms within a text group (file index) where those relationships might be hidden (or potential).
And in that context, it seems like this could be very important for SEO.
right?
After all, Google is a huge index of information, and we hear all sorts of things about semantic search and the importance of relevance in the search ranking algorithm.
If you’ve heard rumblings about semantic indexing lurking in SEO or been advised to use LSI keywords, you’re not alone.
But will LSI actually help improve your search rankings? lets take alook.
Claim: latent semantic indexing as a ranking factor
The claim is simple: optimizing web content with LSI keywords helps Google understand it better and you’ll get higher rankings.
Backlinko defines LSI keywords this way:
“LSI (Latent Semantic Indexing) keywords are conceptual related terms that search engines use to deeply understand the content on a web page.”
By using contextual terms, you can deepen Google’s understanding of your content. Or so the story goes.
This resource goes on to make some very convincing arguments for LSI keywords:
- “Google relies on LSI keywords to understand the contentt at such a deep level.”
- “LSI words are not synonyms. Instead, they are terms closely related to your target keyword.
- “Google isn’t just about bold terms that match perfectly What did you just search for (in the search results). They are also similar bold words and phrases. Needless to say, these are the LSI keywords you’ll want to sprinkle in your content. “
Does the practice of “spraying” terms closely related to your target keyword help improve your rankings across LSI?
Evidence for LSI as a rating agent
Relevancy is determined as one of five main factors that help Google decide which result is the best for any given query.
As Google explains in the How does the search work? the supplier:
To return relevant results for your query, we first need to specify the information you’re looking for – the intent of your query.
Once the intent is set:
“…algorithms analyze the content of web pages to assess whether the page contains information that may be relevant to what you are looking for”.
Google goes on to explain that the relevant “primary signal” is that the keywords used in a search query appear on the page. This makes sense – if you’re not using the keywords the searcher is looking for, how can Google tell you you’re the best answer?
Now, this is where some believe LSI is at play.
If keyword use is an indication of relevance, use Just the right keywords It should be a stronger signal.
There are tools specifically designed to help you find these LSI keywords, and believers in this tactic recommend using all sorts of other keyword research methods to identify them as well.
Evidence against LSI as a rating agent
Google’s John Mueller was quite clear on this:
“…we don’t have a concept of LSI keywords. So that’s something you can completely ignore.”
There is a healthy suspicion in SEO that Google might say things that lead us astray in order to protect the integrity of its algorithm. So let’s dig in here.
First, it is important to understand what LSI is and where it comes from.
Latent semantic architecture as a methodology for retrieving textual objects from files stored in a computer system emerged in the late 1980s. As such, it is an example of one of the earlier information retrieval concepts available to programmers.
As computer storage improved and the amount of data sets available electronically grew, it became difficult to pinpoint exactly what one was looking for in that set.
The researchers described the problem they were trying to solve in a file patent application Submitted September 15, 1988:
“Most systems still require a user or information provider to define explicit relationships and links between data objects or text objects, which makes systems tedious to use or to apply to large, heterogeneous computer information files whose content may be unfamiliar to the user.”
IR keyword matching was used at the time, but its limitations were apparent long before Google came along.
Often, the words a person used to search for the information they were looking for were not an exact match to the words used in the indexed information.
There are two reasons for this:
- synonymThe variety of words used to describe a single object or idea that leads to a loss of relevant consequences.
- polysemy: Different meanings of a single word lead to the retrieval of irrelevant results.
These are still issues today, and you can imagine what a huge headache it was for Google.
However, the methodologies and techniques used by Google to solve relevance have long since migrated from LSI.
What LSI does is automatically create a “semantic space” for information retrieval.
As the patent explains, LSI treats this unreliability of correlation data as a statistical problem.
Without getting into the weeds, these researchers basically believed that there was a hidden underlying semantic structure that they could glean from the word usage data.
Doing so will reveal the underlying meaning and enable the system to return more relevant results – and Just The most relevant results – even if there isn’t an exact match for the keywords.
Here’s what this LSI process looks like in reality:
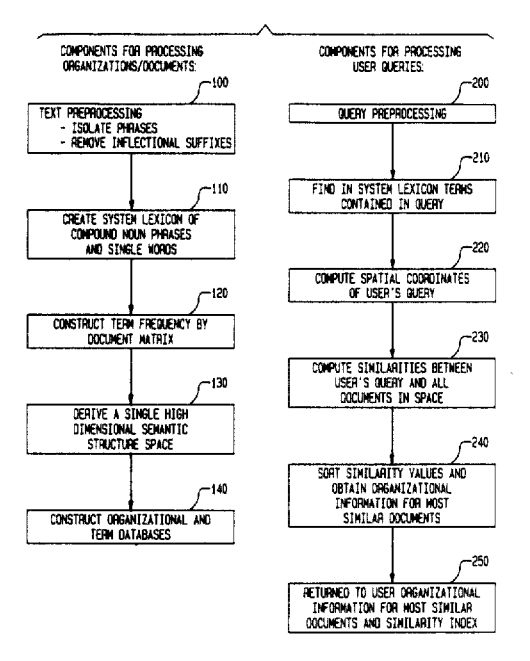
Here’s the most important thing to note about the above illustration of this methodology from the patent application: There are two separate processes that occur.
First, the collection or index undergoes latent semantic analysis.
Second, the query is parsed and then similarities are looked for in the already processed index.
And herein lies the fundamental problem with LSI as an indication of Google’s search ranking.
Google index is particle in a Hundreds of billions pages, and it is constantly growing.
Every time a user enters a query, Google sorts through its index in a split second to find the best answer.
Using the above methodology in the algorithm requires Google to:
- Recreate that semantic space using LSA across its entire index.
- Semantic analysis from the query.
- Find all similarities between the semantic meaning of the query and documents in the semantic space generated from the analysis of the entire index.
- Sort and arrange those results.
This is a gross simplification, but the point is that this is not a scalable process.
This will be very useful for small groups of information. It was useful for highlighting relevant reports within the company’s computerized archive of technical documentation, for example.
The patent application shows how LSI works using a set of nine documents. This is what it was designed to do. LSI is primitive in terms of computerized information retrieval.
Latent semantic indexing as a classification factor: our judgment

While the basic principles of removing confusion through determining semantic relevance have certainly informed developments in search ranking since LSA/LSI was patented, LSI itself has no useful application in SEO today.
It’s not entirely ruled out, but there is no evidence that Google ever used LSI to rank results. And Google certainly doesn’t use LSI or LSI keywords today to rank search results.
Those who recommend using LSI keywords stick to a concept they don’t fully understand in an attempt to explain why the ways in which words relate (or not) matter to SEO.
Relevancy and intent are primary considerations in the Google search ranking algorithm.
These are two of the biggest questions that they are trying to solve in bringing out the best answer for any query.
Synonyms and polysemy remain major challenges.
Semantics – our understanding of the different meanings of words and how they relate – is essential to producing more relevant search results.
But LSI has nothing to do with that.
Featured Image: Paolo Bobita/Search Engine Magazine
![Ranking factors: fact or fiction? Let's bust some myths! [Ebook]](https://altwhed.com/wp-content/uploads/2023/01/Internal-Links-As-A-Ranking-Factor-What-You-Need-To.jpg)





