We’ve all been in a situation where we’ve had to extract data from a website at some point.
When working on a new account or campaign, you may not have the data or information available to create ads, for example.
In a perfect world, it would have provided us with all the content, landing pages, and related information we need, in an easy-to-import format like a CSV file, Excel spreadsheet, or Google Spreadsheet. (Or at least, provide what we need as tabbed data that can be imported into one of the above formats).
But this is not always the case.
Those who lack web scraping tools – or coding knowledge to use something like Python to help with the task – will probably have to resort to the tedious task of manually copying and pasting perhaps hundreds or thousands of entries.
In a recent job, my team was asked to:
- Go to the client’s website.
- Download over 150 new products spread across 15 different pages.
- Copy and paste the product name and landing page URL for each product into a spreadsheet.
Now, you can imagine how long the task would have taken if we had done just that and done the task manually.
Not only is it time consuming, but with someone manually going through so many items and pages and actually having to copy and paste data product by product, the chances of making a mistake or two are very high.
It will take more time to review the document and make sure it is error-free.
There is definitely a better way.
Good news: there! Let me show you how we did it.
What is IMPORTXML?
Enter Google Sheets. I would like you to learn about the IMPORTXML function.
According to Google Support pageIMPORTXML “Imports data from any of the various structured data types including XML, HTML, CSV, TSV, RSS, and ATOM XML feeds.”
Essentially, IMPORTXML is a function that allows you to scrape structured data from web pages – no coding knowledge required.
For example, it is quick and easy to extract data such as page titles, descriptions or links, but also more complex information.
How can IMPORTXML help scrape web page elements?
The function itself is very simple and requires only two values:
- The URL of the web page from which we intend to extract or scrape information.
- The XPath of the element the data contains.
XPath mean XML Path Language They can be used to navigate through elements and attributes in an XML document.
For example, to extract the page address from https://en.wikipedia.org/wiki/Moon_landing, we’ll use:
=IMPORTXML (“https://en.wikipedia.org/wiki/Moon_landing”, “//title”)
This will return the value: Moon landing – Wikipedia.
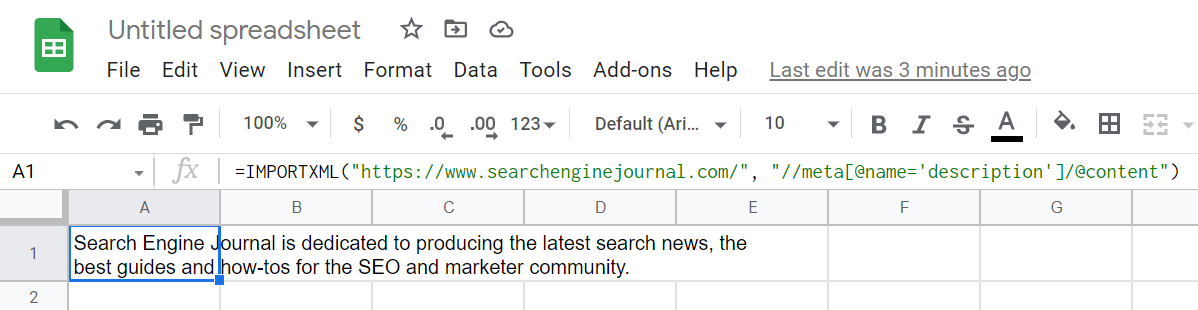
Or, if we’re looking for a page description, try the following:
= IMPORTXML (“https://www.searchenginejournal.com/”, “// meta[@name=’description’]/@Content”)
Here is a short list of some of the most popular and useful XPath queries:
- Page title: // title
- Page meta description: // meta[@name=’description’]/@Content
- Page H1://h1
- Page links: // @ href
See IMPORTXML in action
Since the discovery of IMPORTXML in Google Sheets, it has truly become one of our secret weapons in automating many of our daily tasks, from creating campaigns and ads to researching content and more.
Moreover, the combined function can be used with formulas and other add-ons for more advanced tasks that require high-end solutions and development, such as Python’s built-in tools.
But in this case, we’ll be looking at IMPORTXML in its simplest form: scraping data from a web page.
Let’s look at a practical example.
Imagine that we are asked to create a campaign for a search engine magazine.
They want us to announce the last 30 articles published under the PPC section of the site.
You might say it is a very simple task.
Unfortunately, the editors are unable to send us data and have asked us to consult the website for the information required to set up the campaign.
As we mentioned at the beginning of our article, one way to do this is to open two browser windows – one with the website, and the other with Google Sheets or Excel. We’ll then start copying and pasting information, article by article, and link by link.
But by using IMPORTXML in Google Sheets, we can achieve the same output with little or no risk of making mistakes, in a fraction of the time.
Here’s how.
Step 1: Start with a fresh Google Sheet
First, we open a new, blank document in Google Sheets:
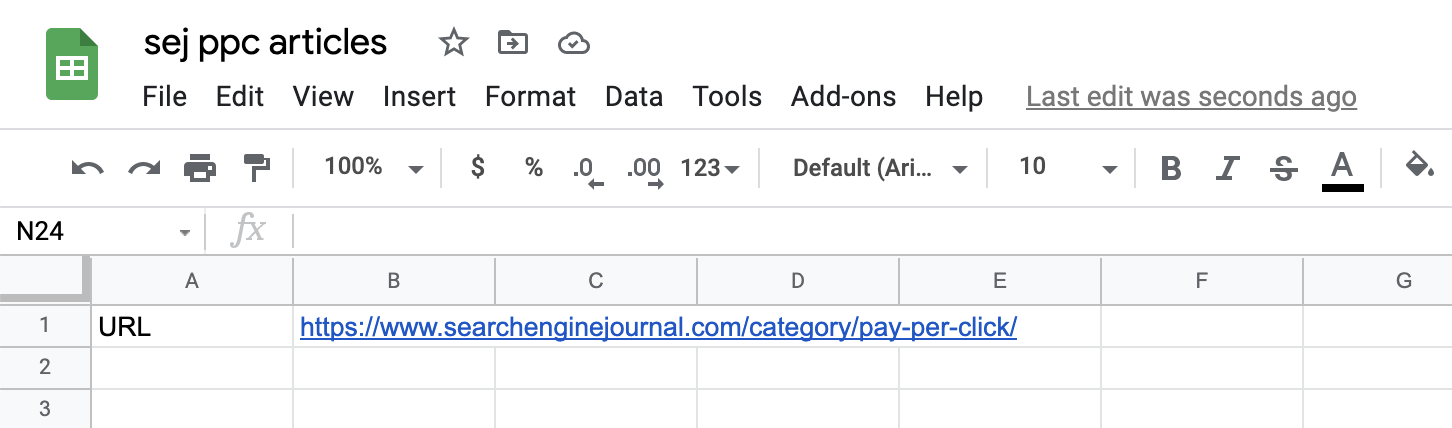
Step 2: Add the content you want to scrape
Add the URL of the page (or pages) we want to scrape information from.
In our case, we start with https://www.searchenginejournal.com/category/pay-per-click/:
 Screenshot from Google Sheets, July 2021
Screenshot from Google Sheets, July 2021Step 3: Find the XPath file
We find the XPath of the element from which we want to import content into our spreadsheet.
In our example, let’s start with the titles of the 30 most recent articles.
Head over to Chrome. Once you hover over the title of an article, right-click and select check up.
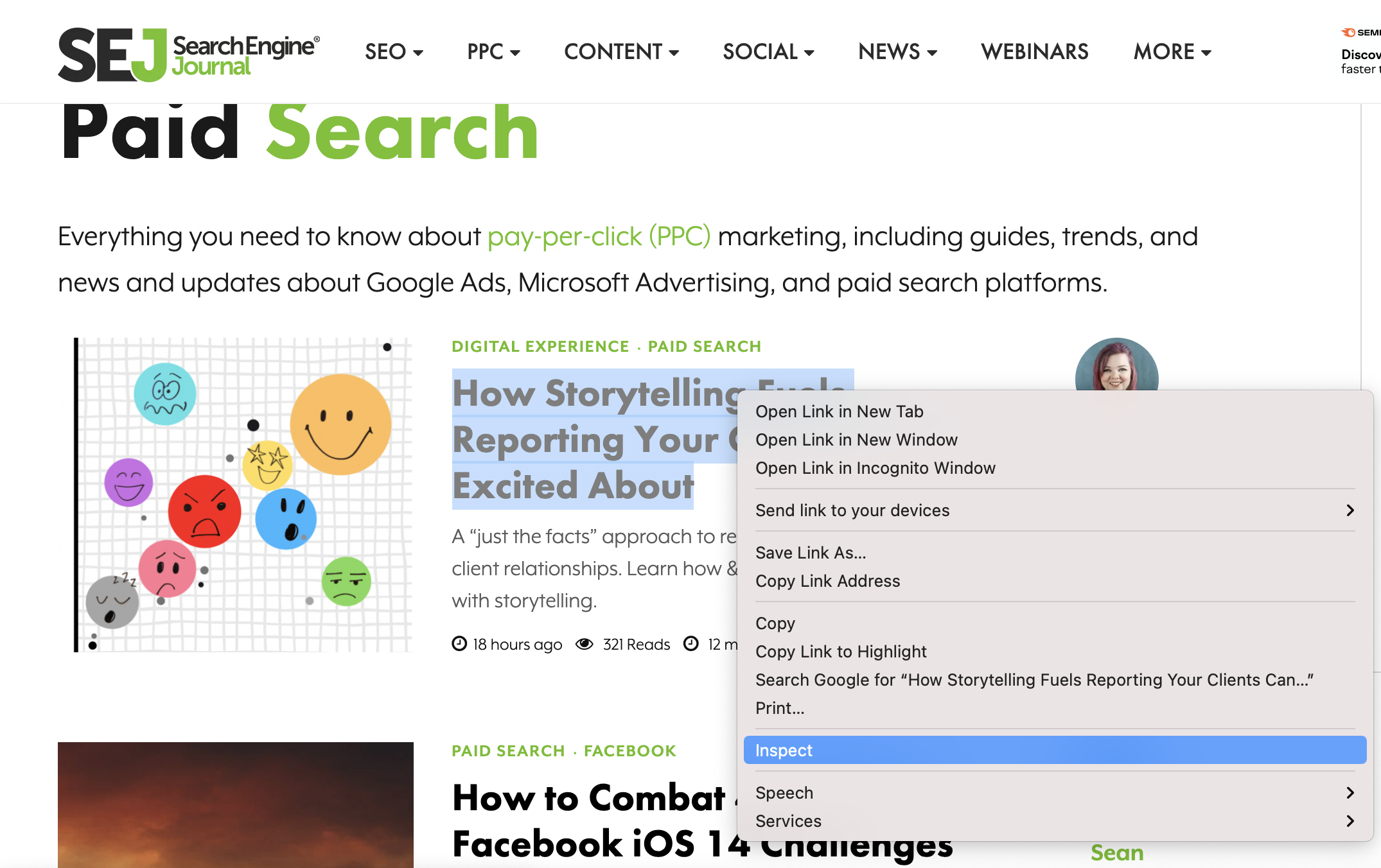 Screenshot from SearchEngineJournal.com, July 2021
Screenshot from SearchEngineJournal.com, July 2021This will open the Chrome Dev Tools window:
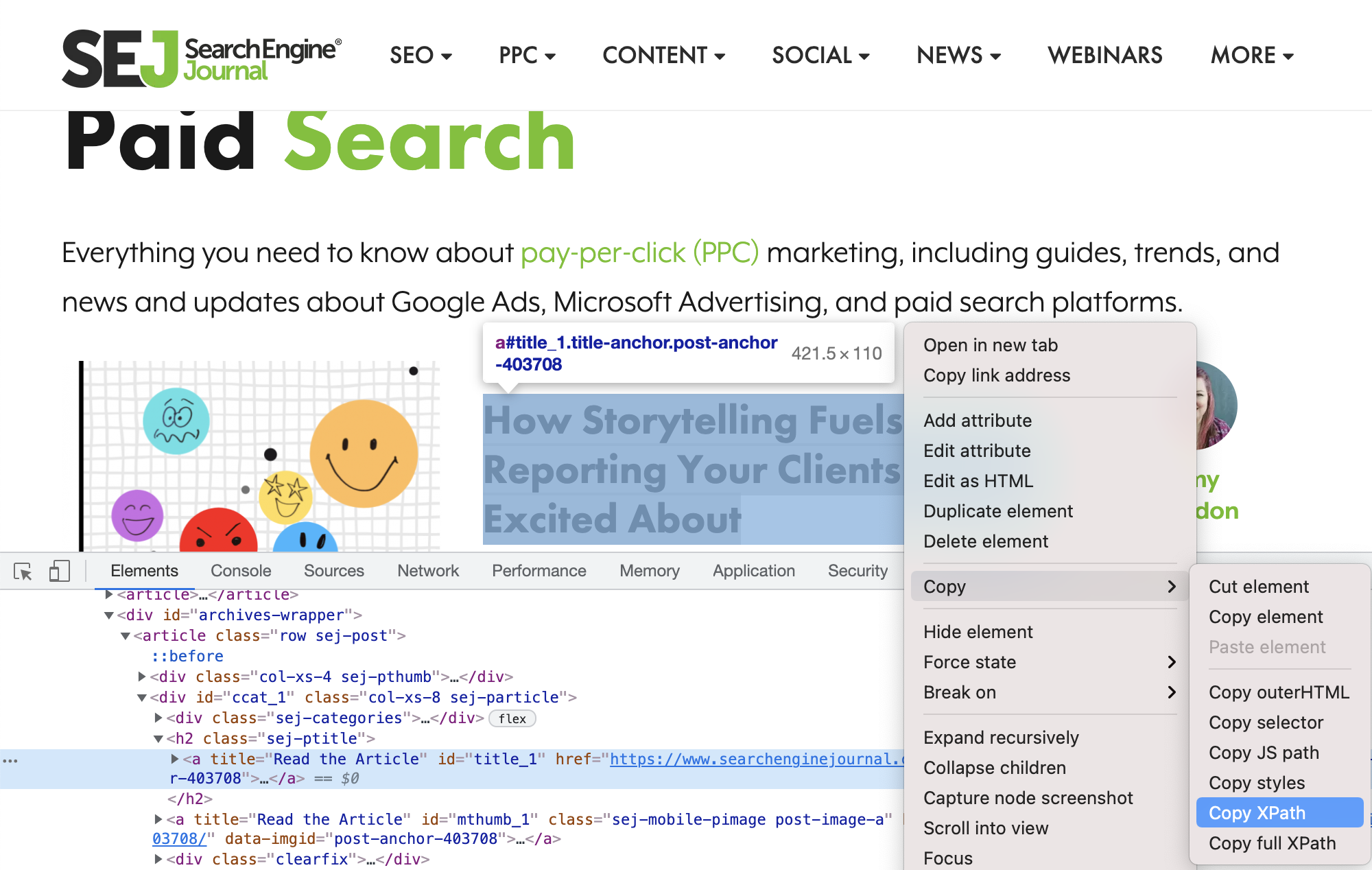 Screenshot from SearchEngineJournal.com, July 2021
Screenshot from SearchEngineJournal.com, July 2021Make sure the article title is still selected and highlighted, then right-click again and select Copy > Copy XPath.
Step 4: Extract the data in Google Sheets
Back in your Google Sheets document, introduce the IMPORTXML function like this:
=IMPORTXML(B1,” “//*[starts-with(@id, ‘title’)]”)
A couple of things to note:
Firstin our formula, we’ve replaced the page URL with a reference to the cell where the URL is stored (B1).
a secondwhen copying XPath from Chrome, this will always be enclosed in quotes.
(// *[@id=”title_1″])
However, to ensure that it does not break the syntax, the double quote must be changed to the single quote.
(// *[@id=’title_1’])
Note that in this case, since the title of the page-id changes for each article (heading_1, title_2, etc.), we have to modify the query a bit and use ‘starts with’ to capture all elements on the page with an id that contains ‘title.’
Here’s what it looks like in a Google Sheets document:
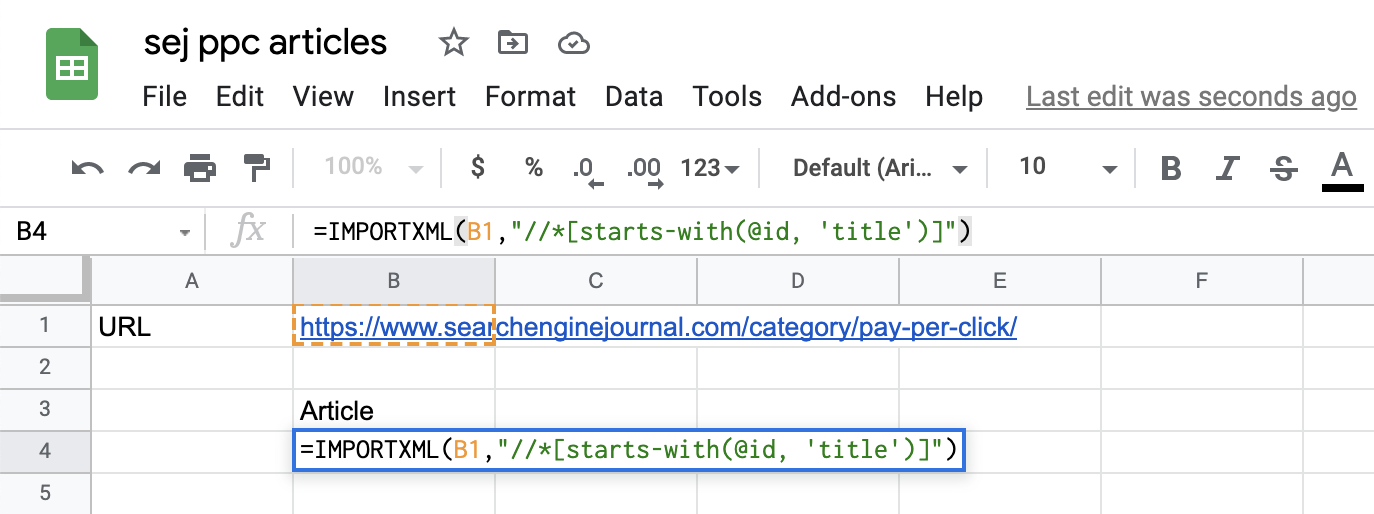 Screenshot from Google Sheets, July 2021
Screenshot from Google Sheets, July 2021And in a few moments, this is what the results look like after loading the query on the data in the spreadsheet:
 Screenshot from Google Sheets, July 2021
Screenshot from Google Sheets, July 2021As you can see, the list shows all of the articles that appeared on the page we just scraped (including my previous article on automation and how to use ad customizers to improve Google Ads campaign performance).
You can apply this to omit any other information you need to set up your ad campaign as well.
Let’s add the landing page URLs, the featured snippet for each article, and the author’s name in our spreadsheet document.
For landing page URLs, we need to modify the query to specify that we are after the HREF element attached to the article title.
So, our query will look like this:
=IMPORTXML(B1,” “//*[starts-with(@id, ‘title’)]/@href”)
Now, append “/@href” to the end of the Xpath.
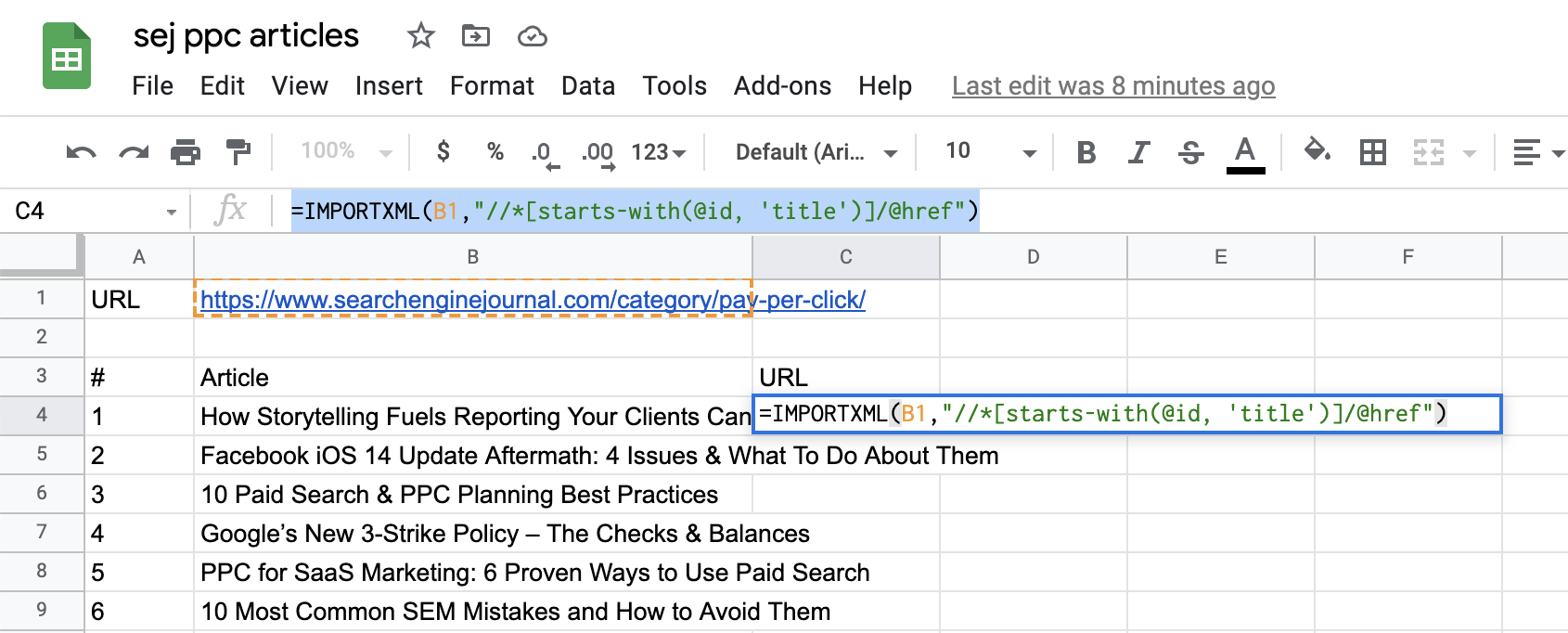 Screenshot from Google Sheets, July 2021
Screenshot from Google Sheets, July 2021there he is! Right off the bat, we have the landing page URLs:
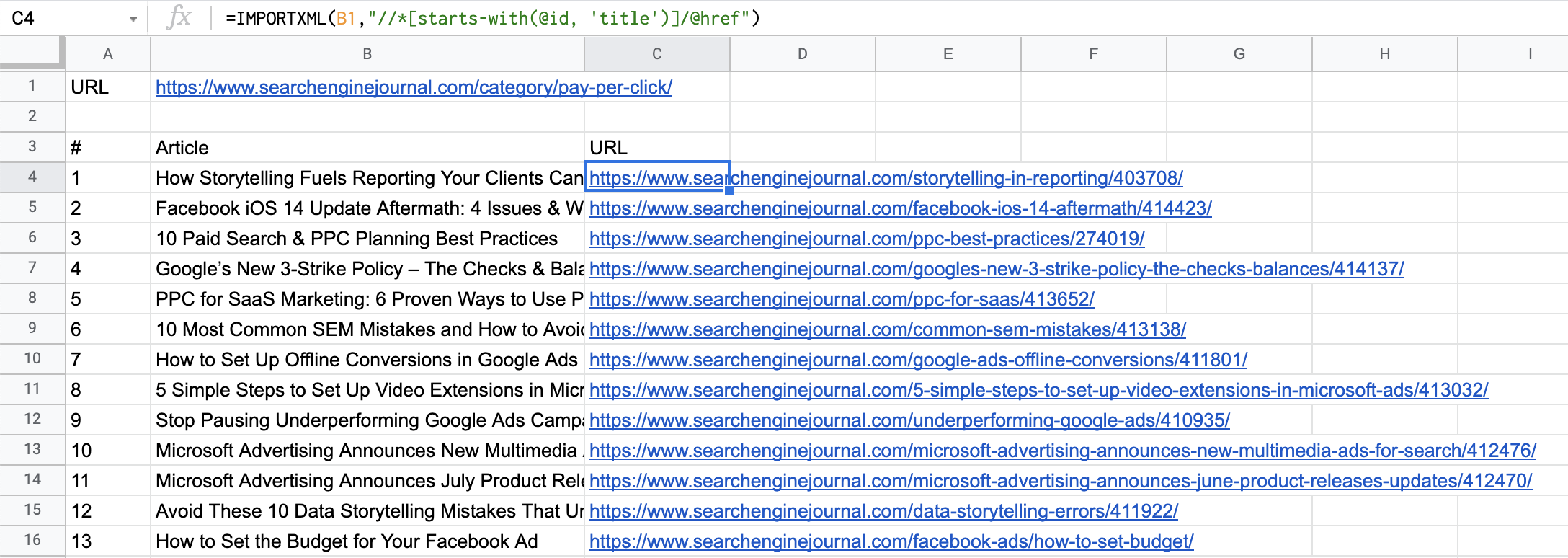 Screenshot from Google Sheets, July 2021
Screenshot from Google Sheets, July 2021You can do the same with featured snippets and author names:
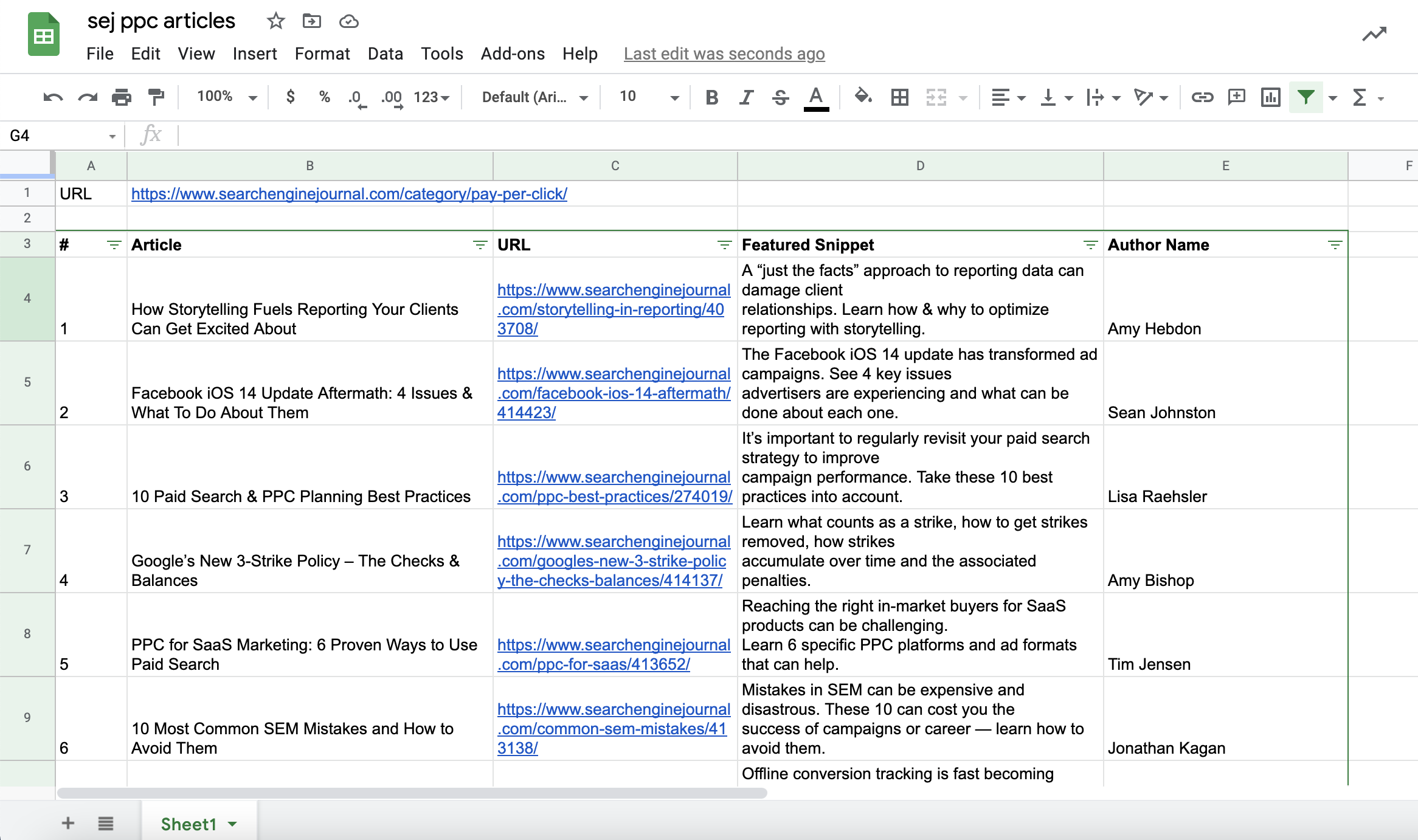 Screenshot from Google Sheets, July 2021
Screenshot from Google Sheets, July 2021find the mistakes and resolve it
One thing to be careful of is that in order for you to expand the entire spreadsheet and populate it with all the data returned by the query, the column in which the data is populated must have enough cells free and no other data in the way.
This works in a similar way when we use ARRAYFORMULA, in order for the formula to expand there must be no other data in the same column.
conclusion
And there’s a fully automated and error-free way to scrape data from (potentially) any web page, whether you need content and product descriptions, or e-commerce data like product price or shipping costs.
While information and data can be the feature needed to deliver better-than-average results, the ability to scrape web pages and structured content in an easy and fast way can be invaluable. Besides, as we saw above, IMPORTXML can help reduce execution times and reduce the chances of making errors.
Additionally, the functionality is not only a great tool that can be used exclusively for PPC tasks, but instead can be really useful across many different projects that require web scraping, including SEO and content tasks.
Christmas Countdown to 2021 SEJ:
- #12 – The New Google Business Profile: A Complete Guide to Local SEO
- #11 – How to Automate SEO Keyword Clustering by Search Intent Using Python
- #10 – Get to Know Google Analytics 4: A Complete Guide
- #9 – 7 things I wish I knew earlier in my SEO career
- #8 – A Guide to Optimizing Google News, Top Stories, and Discovery
- #7 – Keyword Combinations: How to Elevate Your SEO Content Strategy
- #6 – Advanced Basic Web Basics: A Technical Guide to SEO
- #5 – How to use Google Sheets for web scraping and campaign building
Featured image: Aliotti/Shutterstock